 2 часов назад
1
2 часов назад
1
Стартап Subquadratic из Майами вышел из «режима скрытой разработки» с заявлением о том, что ему удалось устранить одно из фундаментальных вычислительных ограничений больших языковых моделей, связанное с квадратичной сложностью механизма внимания в трансформерах.
Компания представила модель SubQ, которая, по её утверждениям, способна обрабатывать значительно большие объёмы текста при меньших затратах вычислений и энергии, а также обеспечивать кратный рост скорости работы на длинных контекстах. Речь идёт о возможности анализа сотен документов или больших кодовых баз за один проход.
Однако первоначально Subquadratic предоставила ограниченное количество подтверждений — в основном внутренние тесты, что вызвало скепсис в ИИ-сообществе. Часть специалистов сравнила ситуацию с громкими, но неподтверждёнными технологическими заявлениями, указывая на отсутствие открытого доступа к модели и независимых проверок.
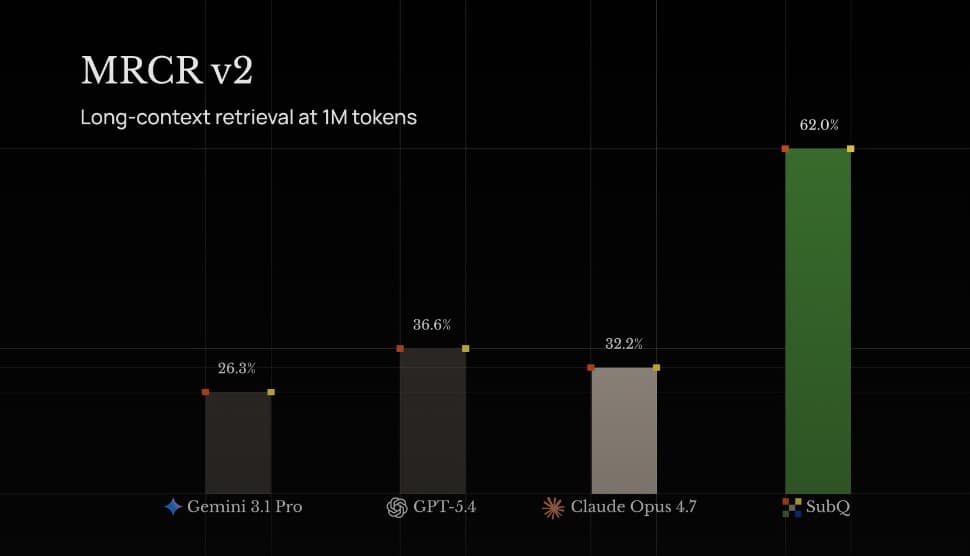
Позднее компания опубликовала дополнительные результаты, включая независимое тестирование, проведённое сторонней оценочной компанией Appen [поставщик услуг по тестированию и разметке данных для ИИ-моделей]. В отчётах утверждается, что SubQ демонстрирует высокую скорость работы и конкурентоспособные результаты на ряде задач, включая программирование.
 Источник: Subquadratic
Источник: Subquadratic
В основе заявленного улучшения лежит отказ от стандартного механизма dense attention, используемого в трансформерах, в пользу варианта sparse attention. В классических LLM каждый элемент текста взаимодействует со всеми остальными, что приводит к квадратичному росту вычислений при увеличении длины контекста. Subquadratic утверждает, что её подход выбирает только часть таких взаимодействий, снижая нагрузку.
При этом компания заявляет, что SubQ способен обрабатывать до 12 млн токенов контекста, тогда как большинство современных моделей ограничены примерно 1 млн. В демонстрациях также утверждается, что модель может работать с сотнями документов одновременно и выполнять задачи извлечения информации на больших массивах данных значительно быстрее конкурентов.
Отдельный акцент сделан на тестах скорости и эффективности: по данным Appen, SubQ демонстрировал кратный рост скорости обработки по сравнению с подходами на основе FlashAttention, а также высокие результаты на бенчмарке LiveCodeBench, оценивающем задачи программирования.
При этом независимые специалисты подчёркивают, что бенчмарки не отражают полноты возможностей модели в реальных сценариях. Также остаётся открытым вопрос, насколько новая архитектура действительно заменяет трансформеры, поскольку Subquadratic частично опирается на существующие открытые модели семейства Qwen, адаптируя их под собственный подход.
Сейчас SubQ доступна ограниченному числу пользователей, включая корпоративных клиентов, компания объясняет это ранней стадией развития и ограниченными ресурсами. Полноценная независимая оценка модели пока невозможна, что сохраняет высокий уровень скепсиса в отношении заявлений о «снятии» ключевого ограничения LLM.
© iXBT









 English (US) ·
English (US) ·  Russian (RU) ·
Russian (RU) ·